GFS 论文解读
GFS 是 Google 于 2003 年发表的经典分布式文件系统论文(《The Google File System》),其系统设计思想深刻影响了后续分布式存储系统的发展(HDFS 即为 GFS 的开源实现)。本节从前提假设、系统架构、一致性模型和系统交互四个方面分析 GFS 的核心设计。
1.1 前提与假设
GFS 在设计之初就明确了其与众不同的假设条件,这些假设决定了 GFS 很多与传统文件系统截然不同的设计决策:
- 节点/组件失效是常态:廉价的商用服务器随时可能故障,因此监控、异常检测、容错和自动恢复是系统必备特性,而非可选增强
- 存储文件尺寸较大,通常是 GB 级别:IO 操作和 block size 需要针对大文件重新设计
- 写文件主要是 append 操作,随机写几乎不存在;读文件主要是顺序读,随机读较少:需要关注写的原子性,并针对 append 进行深度性能优化
- 系统设计主要关注高吞吐量(throughput),而不是低响应延迟(latency):批量数据处理场景下吞吐量远比单次延迟重要
1.2 系统架构
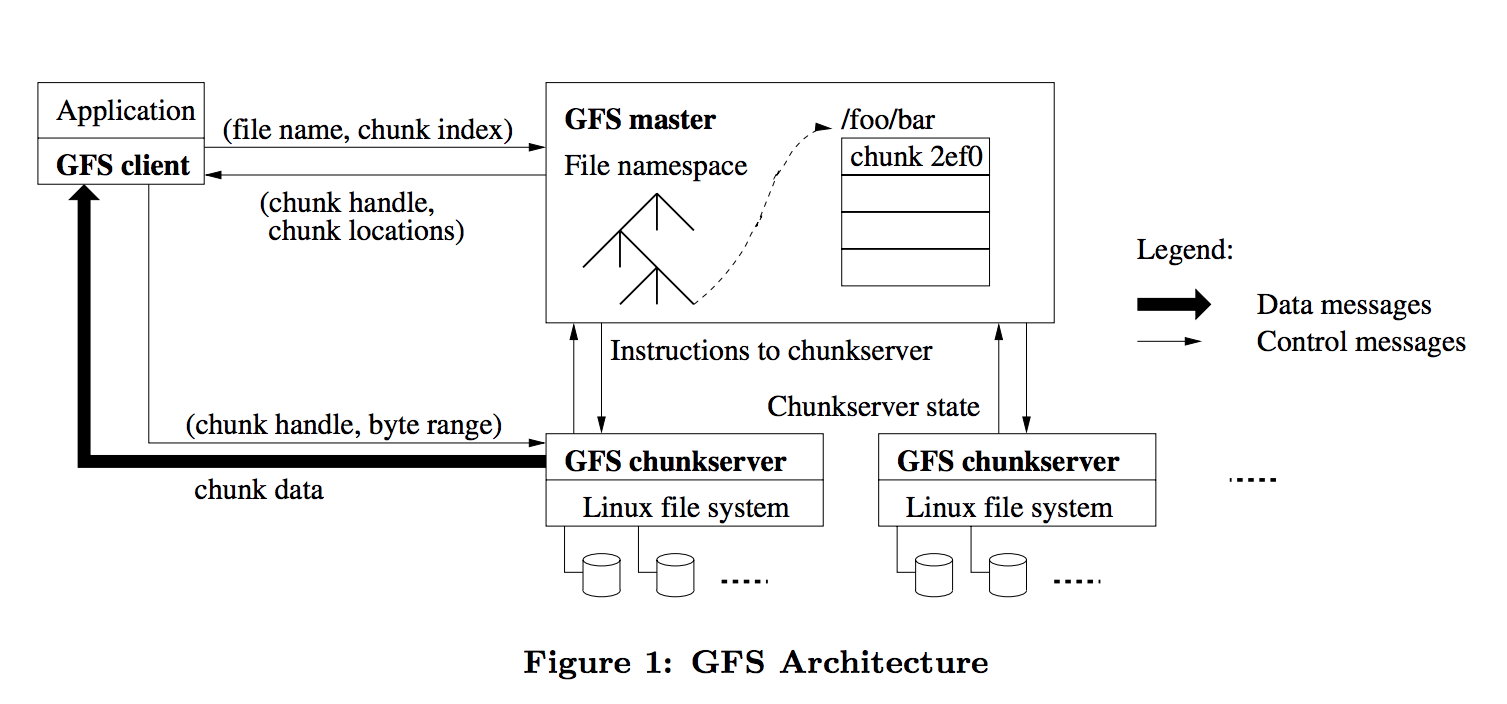
GFS 集群由一个 Master 和多个 Chunkserver 组成,被多个 Client 访问。文件被分割为固定大小的 chunk。
- chunk:文件存储在固定大小的 chunk 中,每个 chunk 由一个全局唯一的 64 位 chunk handle 标识
- Master:维护文件系统的所有元数据,包括 namespace(文件命名空间)、access control 信息、文件到 chunk 的映射、所有 chunk 的当前位置。同时控制系统活动,包括 chunk lease management(租约管理)、孤立 chunk 的垃圾回收、chunkserver 之间的 chunk 迁移。Master 与 chunkserver 之间通过 HeartBeat 心跳信息进行通信,包括下达指令和收集状态
- Chunkserver:出于可靠性的考虑,chunk 一般在多个 chunkserver 上进行 3 副本存储。Chunkserver 不缓存文件——因为 Linux 系统的 buffer cache 已经缓存了热点数据,在 chunkserver 上再做一层缓存没有额外收益
- Client:客户端不针对文件进行缓存,只对元数据进行缓存。原因:大部分应用需要扫描大文件,太大无法缓存;不做缓存也自然避免了缓存一致性问题
1.2.1 Chunk Size
GFS 的 chunk size 为 64MB,远大于典型文件系统的 block size。利用 lazy space allocation(延迟空间分配)避免了内部碎片造成的空间浪费。
较大的 chunk size 提供了以下好处:
- 减少 Client 与 Master 的交互次数(一次交互可获取更大的操作范围)
- Client 与 Chunkserver 保持较长的 TCP 持久连接,减少连接建立开销
- 减小 Master 上存储的元数据体积,使元数据可以全部存储在内存中,带来极快的查找性能
副作用:一个小文件可能仅占用一个 chunk,当多客户端同时访问该文件时,承载该 chunk 的 chunkserver 会成为热点。
1.2.2 元数据(Metadata)
Master 存储三种类型的元数据:
- 文件和 chunk 的 namespace
- 文件到 chunk 的映射
- 每个 chunk 的副本位置
前两种元数据通过 operation log 持久化存储在 Master 的本地磁盘,并备份到远程机器上。
Chunk Locations
Master 不持久化存储 chunk 位置信息——而是在启动时以及 chunkserver 加入集群时,通过询问 chunkserver 来获取其持有的 chunk 列表。这种设计避免了 Master 与 chunkserver 之间因为保持 chunk 位置信息一致而带来的复杂性(chunkserver 自身就是 chunk 位置的最权威信息源)。
Operation Log
operation log 不仅是元数据的唯一持久化存储,也定义了并发操作的逻辑时间线——文件和 chunk 以及它们的版本都可以通过逻辑创建时间来唯一确定。
元数据的变更需要在对客户端可见之前完成持久化(写入本地磁盘并同步到远程机器),Master 通过批量收集日志记录来减少对系统吞吐量的影响。
Master 通过重放 operation log 来恢复文件系统状态。为缩短恢复时间,当 operation log 超过特定大小时,Master 会保存一个 checkpoint——恢复时只需加载最近的 checkpoint 并重放其后的 log。Checkpoint 以类似 B 树的形式组织,能够直接映射到内存中并且不需要额外解析就能用于 namespace 查找。生成 checkpoint 时,Master 切换到新的 operation log 文件,并在单独线程中异步创建 checkpoint;恢复时会验证 checkpoint 的完整性,跳过不完整的 checkpoint。
1.3 一致性模型
1.3.1 保障(Guarantees)
文件 namespace 的修改(例如文件的创建)保证原子性——这些操作全部由 Master 处理:namespace 加锁保证原子性和正确性,operation log 定义了这些操作的全局总序。
文件块在修改之后的状态取决于修改的类型、是否成功、是否是并发操作。下表总结了各种情况下的结果:
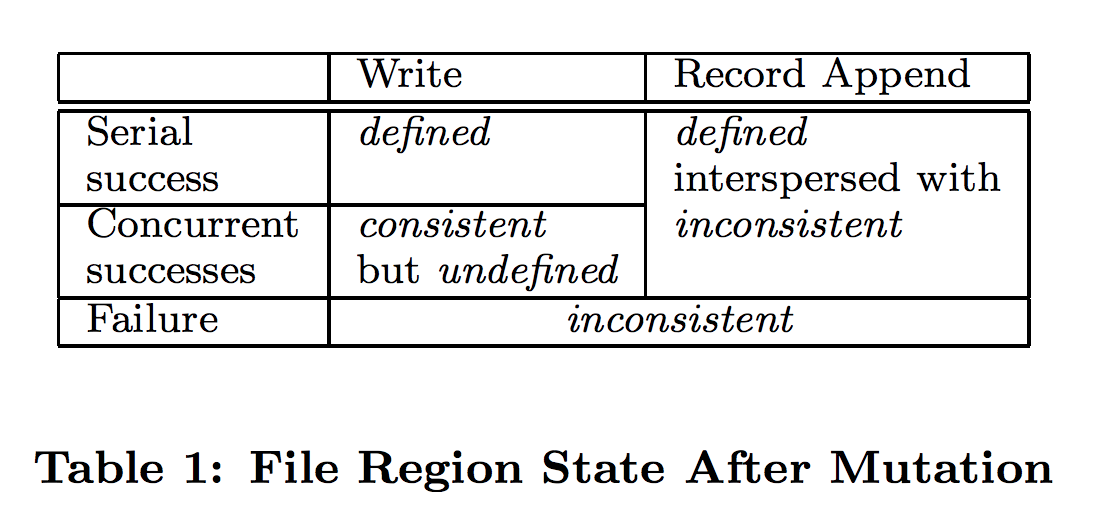
其中 defined 表示文件块是一致的,并且对其的修改是完整可见的。随机写由于可能覆盖原有数据,因此在并发的情况下不能保证每次操作的可见性(可能出现 consistent but undefined 的状态——所有客户端看到相同的内容,但内容可能是多次写入的交错混合)。
GFS 通过以下两点来保证文件块在一系列成功修改之后的可见性,并保证包含最后一次修改:
- 在其所有副本上按照相同的顺序应用修改
- 使用 chunk version number 检测过期副本(版本号不匹配),过期副本会很快被垃圾回收清除
GFS 通过 Master 与所有 chunkserver 之间的定期握手检测失效的 chunkserver,并通过 checksum 检测数据损坏。一旦问题被发现,数据会从有效副本中恢复。只有在所有副本在 GFS 响应之前都丢失的情况下数据才算真正丢失(时间窗口通常为几分钟),并且 GFS 不会返回损坏的数据,而是返回明确的错误。
1.3.2 对应用层的启示
GFS 的一致性模型是”弱化版”的——它不保证所有场景下的强一致性,而是将部分责任上移到应用层:
- 尽量使用 append 写操作(而非随机写),append 的原子性保证每条记录至少被原子地写入一次
- 应用层采用 checkpoint 机制来标记一致的数据点
- 应用层的记录应能 自我验证(checksum) 和 自我识别(unique identifier),以检测和去除重复或损坏的数据
这种”放宽文件系统一致性要求、由应用层承担部分责任”的设计哲学,是 GFS 能够在廉价硬件上实现高吞吐的核心原因之一。
1.4 系统交互
1.4.1 主副本及写顺序
Master 从一个 chunk 的所有副本中选择一个发放 lease(租约),该副本称为主副本(Primary)。主副本对所有对该 chunk 的写操作选择一个序列化顺序,所有副本按此顺序执行写操作。Master 发放给主副本的 lease 初始超时时间为 60s,后续主副本通过 chunkserver 与 Master 之间的心跳信息发送延长租约的请求。
下图展示了一次写操作的控制流与数据流:
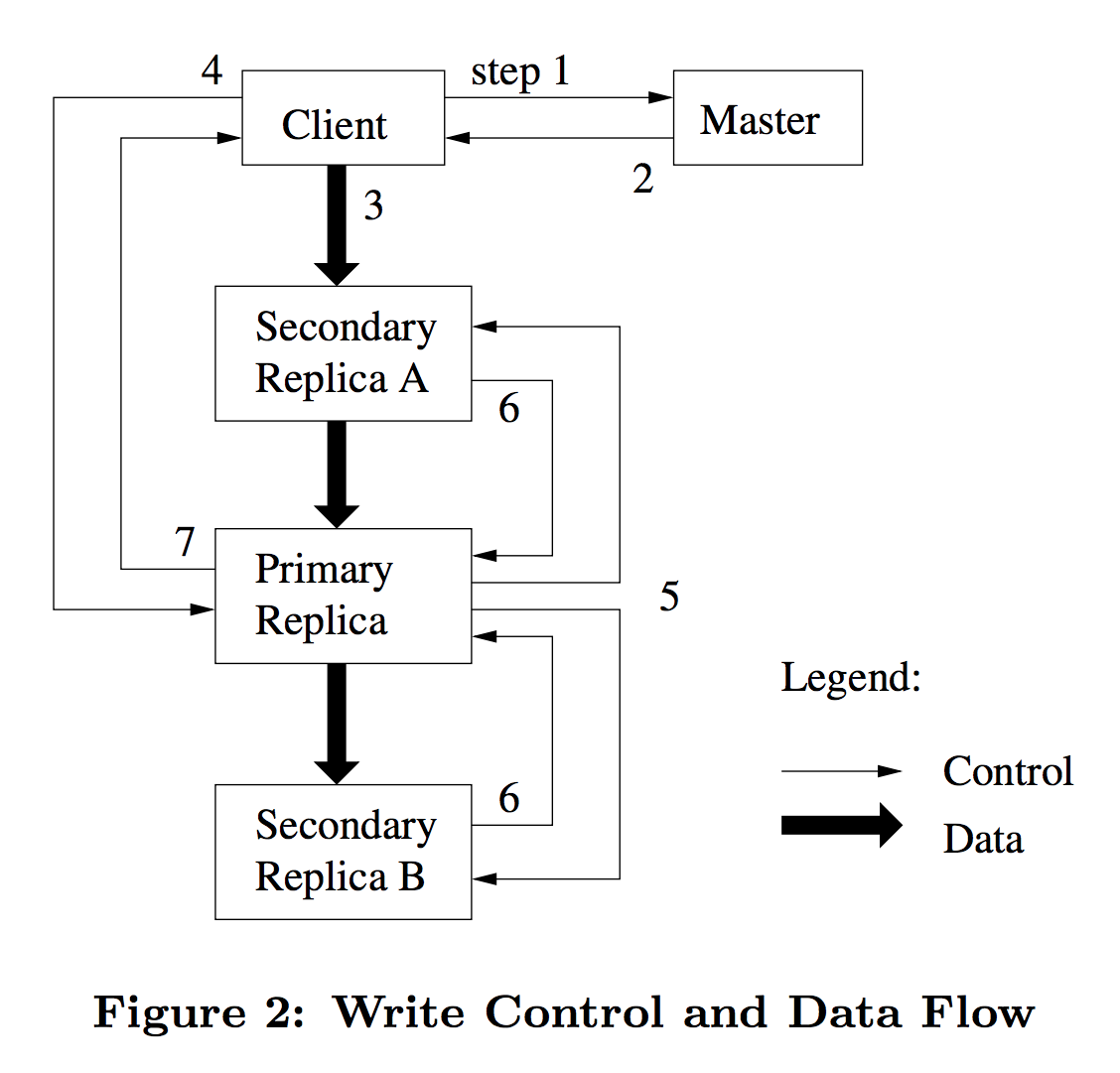
- 步骤 1:Client 向 Master 询问 chunk 的主副本及所有次副本的位置。如当前没有主副本(lease 已过期),Master 选择一个副本下发 lease,使其成为新的主副本
- 步骤 2:Master 响应主副本及次副本的位置,Client 缓存该信息。此后只有当主副本无法访问或主副本响应为不再持有 lease 时,Client 才需要再次访问 Master
- 步骤 3:Client 向所有副本推送数据(以任意顺序),Chunkserver 将数据缓存在 LRU buffer 中
- 步骤 4:Client 发送写请求到主副本,主副本为它收到的所有写操作分配一个连续的序列号,按序列号顺序应用到本地
- 步骤 5:主副本将写请求转发给次副本,次副本按主副本指定的序列号顺序应用
- 步骤 6:次副本响应主副本写入完成
- 步骤 7:主副本响应 Client。若有任何副本写入出错,错误上报给 Client,由 Client 发起重试
注意:过大的写操作或跨越 chunk 边界的写操作,GFS Client 会将其拆分为多个独立的写操作——因此并发写操作可能导致文件块中混杂来自不同 Client 的数据片段。
1.4.2 数据流解耦
GFS 一个关键设计是数据流与控制流的解耦:控制流从 Client → 主副本 → 次副本传递,而数据流以**数据管道(pipeline)**的形式在一条精心选择的 chunkserver 链路上线性传输。这种设计充分利用了每台机器的网络带宽,避开网络瓶颈和高延迟链路,最大化全双工带宽利用率,最小化推送数据的总延迟。
1.5 Master 的操作
1.5.1 Namespace 管理与锁
Master 通过 namespace 锁保证文件操作的原子性和正确性,operation log 定义操作的全局顺序。GFS 的 namespace 是扁平的,没有传统文件系统的目录层级概念——路径只是逻辑上的命名约定,不对应物理目录结构。
1.6 容错与诊断
GFS 在容错方面依赖于三个核心机制:
- Master 高可用:Master 元数据通过 operation log 持久化到本地磁盘并远程备份,配合 shadow master(只读副本)在主 Master 故障时提供只读服务
- Chunk 多副本:chunk 默认 3 副本存储在不同机架的不同 chunkserver 上,任何单点故障不影响数据可用性
- 数据完整性检测:通过 checksum 检测数据损坏并自动从正常副本恢复;通过 chunk version number 检测并回收过期的陈旧副本