JVM GC 算法与收集器 (CMS/G1/ZGC)
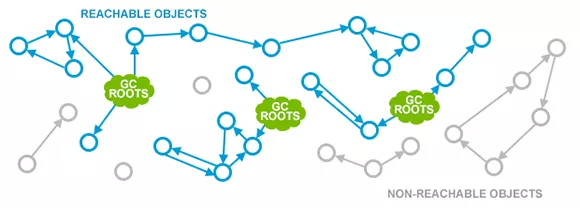
a. GC Roots
可达性分析
a.虚拟机栈(栈桢中的本地变量表)中的引用的对象
b.方法区中的类静态属性引用的对象
c.方法区中的常量引用的对象
d.本地方法栈中JNI的引用的对象
1.System Class ———-Class loaded by bootstrap/system class loader. For example, everything from the rt.jar like java.util.* .
2.JNI Local ———-Local variable in native code, such as user defined JNI code or JVM internal code.
3.JNI Global ———-Global variable in native code, such as user defined JNI code or JVM internal code. 4.Thread Block ———-Object referred to from a currently active thread block. Thread ———-A started, but not stopped, thread.
5.Busy Monitor ———-Everything that has called wait() or notify() or that is synchronized. For example, by calling synchronized(Object) or by entering a synchronized method. Static method means class, non-static method means object.
6.Java Local ———-Local variable. For example, input parameters or locally created objects of methods that are still in the stack of a thread.
7.Native Stack ———-In or out parameters in native code, such as user defined JNI code or JVM internal code. This is often the case as many methods have native parts and the objects handled as method parameters become GC roots. For example, parameters used for file/network I/O methods or reflection. 7.Finalizable ———-An object which is in a queue awaiting its finalizer to be run.
8.Unfinalized ———-An object which has a finalize method, but has not been finalized and is not yet on the finalizer queue.
9.Unreachable ———-An object which is unreachable from any other root, but has been marked as a root by MAT to retain objects which otherwise would not be included in the analysis.
10.Java Stack Frame ———-A Java stack frame, holding local variables. Only generated when the dump is parsed with the preference set to treat Java stack frames as objects.
11.Unknown ———-An object of unknown root type. Some dumps, such as IBM Portable Heap Dump files, do not have root information. For these dumps the MAT parser marks objects which are have no inbound references or are unreachable from any other root as roots of this type. This ensures that MAT retains all the objects in the dump.
b. 常用GC算法
1. mark-sweep 标记清除法
简单快速,易产生内存碎片
2. mark-copy 标记复制法
避免内存碎片,浪费50%内存
3. mark-compact 标记 - 整理(也称标记 - 压缩)法
效率低
4. generation-collect 分代收集算法
以 Hotspot 为例(JDK 7):
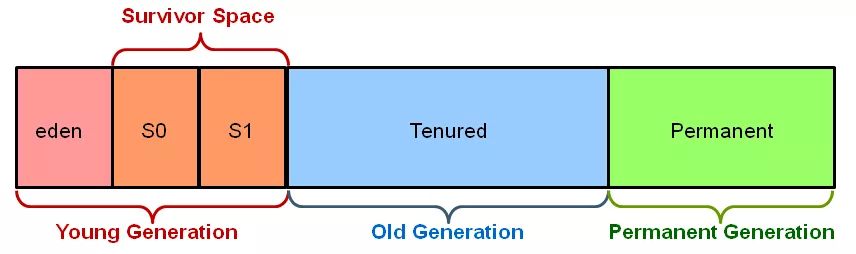
将内存分成了三大块:年青代(Young Genaration),老年代(Old Generation), 永久代(Permanent Generation),其中 Young Genaration 更是又细为分 eden,S0,S1 三个区。
结合我们经常使用的一些 jvm 调优参数后,一些参数能影响的各区域内存大小值,示意图如下:
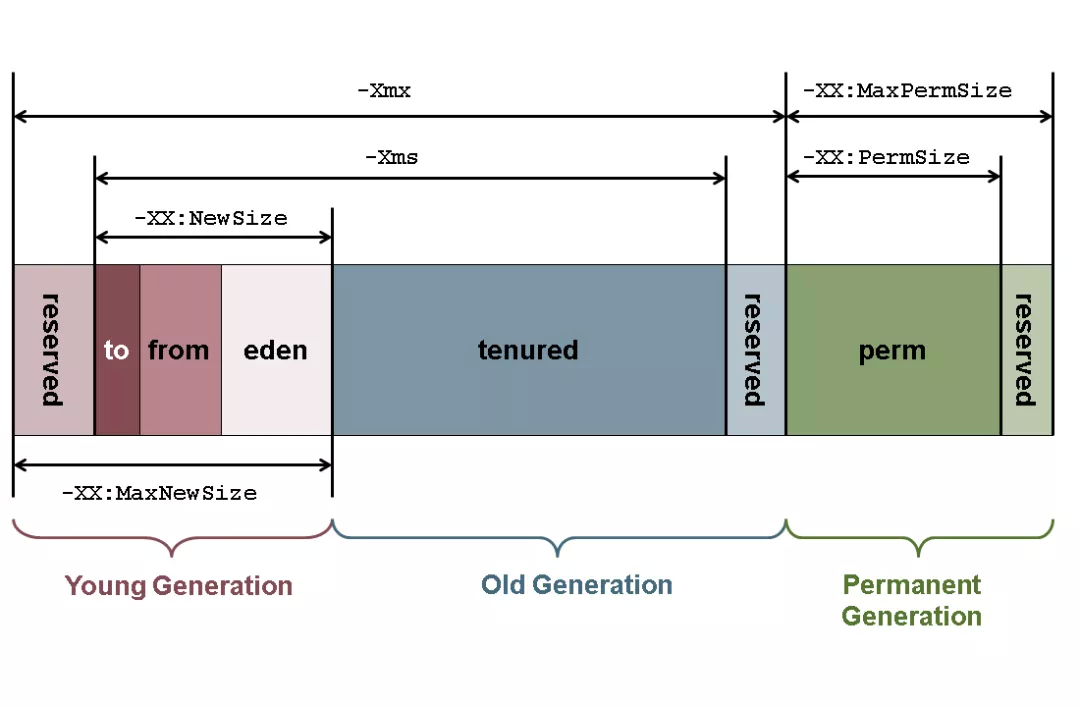
注:jdk8 开始,用 MetaSpace 区取代了 Perm 区(永久代),所以相应的 jvm 参数变成 -XX:MetaspaceSize 及 -XX:MaxMetaspaceSize。
c. GC回收器的各种实现
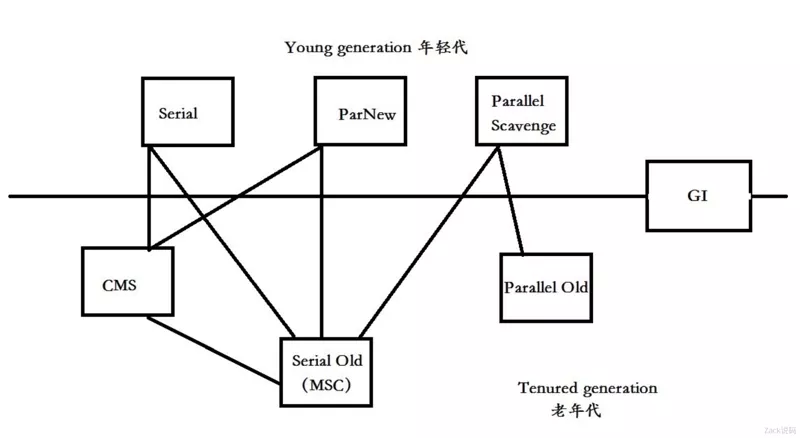
1. Serial 收集器
单线程用标记 - 复制算法,快刀斩乱麻,单线程的好处避免上下文切换,早期的机器,大多是单核,也比较实用。但执行期间,会发生 STW(Stop The World)。
2. ParNew 收集器
Serial 的多线程版本,同样会 STW,在多核机器上会更适用。
3. Parallel Scavenge 收集器
ParNew 的升级版本,主要区别在于提供了两个参数:-XX:MaxGCPauseMillis 最大垃圾回收停顿时间;-XX:GCTimeRatio 垃圾回收时间与总时间占比,通过这 2 个参数,可以适当控制回收的节奏,更关注于吞吐率,即总时间与垃圾回收时间的比例。
4. Serial Old 收集器
因为老年代的对象通常比较多,占用的空间通常也会更大,如果采用复制算法,得留 50% 的空间用于复制,相当不划算,而且因为对象多,从 1 个区,复制到另 1 个区,耗时也会比较长,所以老年代的收集,通常会采用”标记 - 整理”法。从名字就可以看出来,这是单线程(串行)的, 依然会有 STW。
5. Parallel Old 收集器
一句话:Serial Old 的多线程版本。
6. CMS 收集器
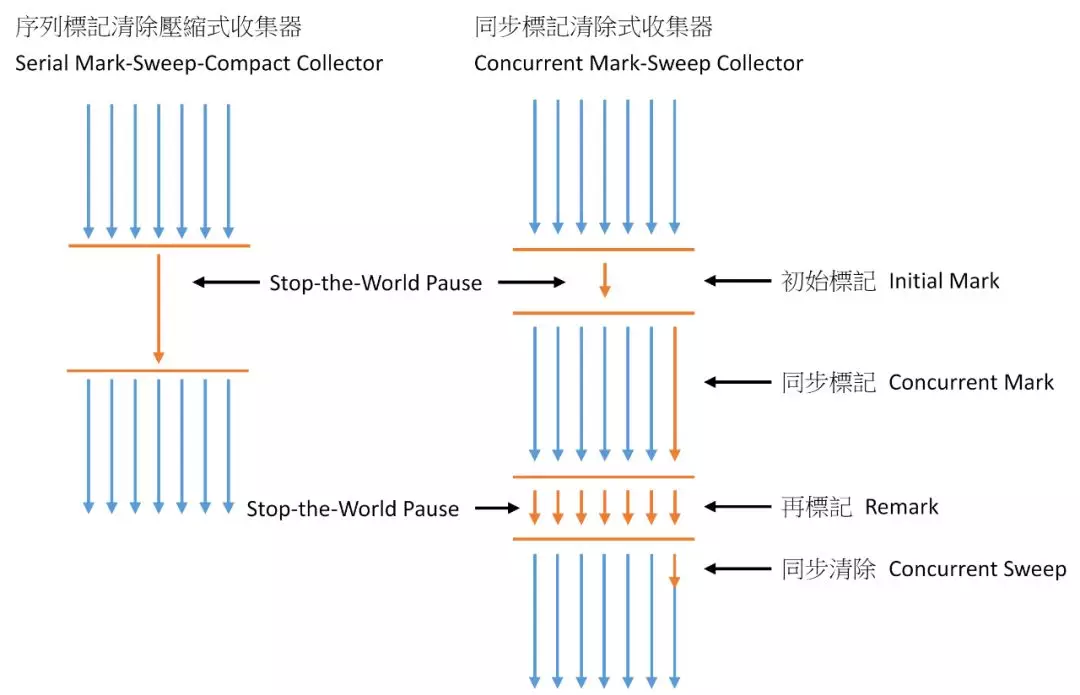
7. G1回收器
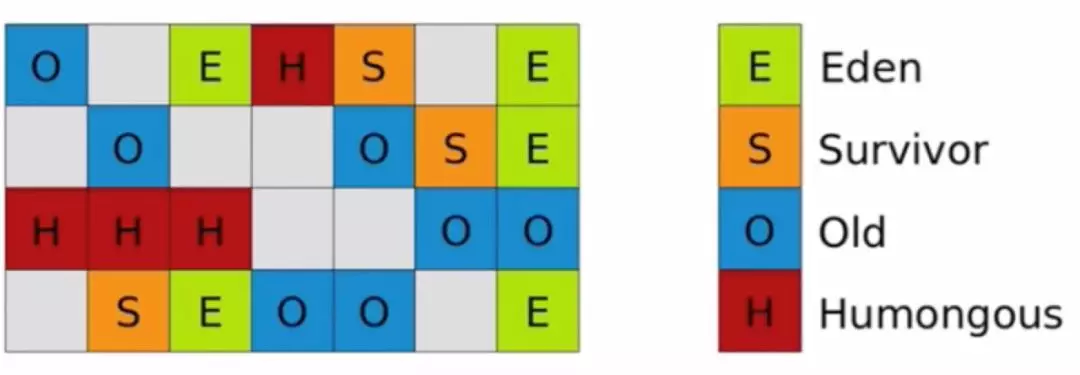
G1 Young GC
young GC 前:
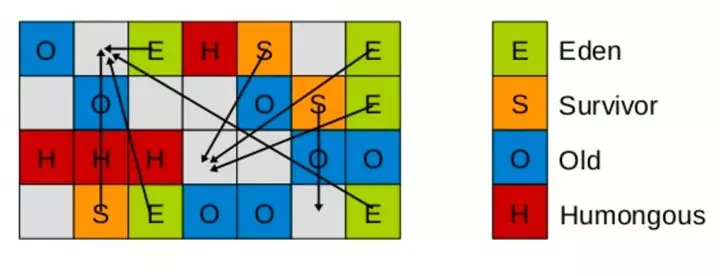
young GC 后:
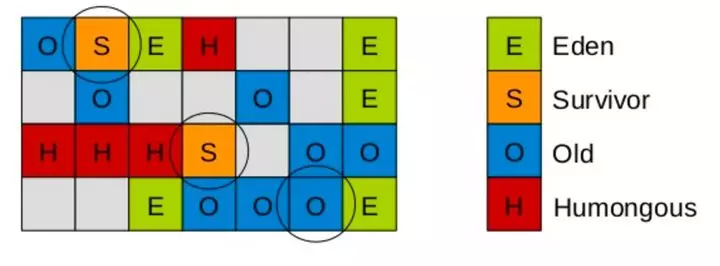
由于 region 与 region 之间并不要求连续,而使用 G1 的场景通常是大内存,比如 64G 甚至更大,为了提高扫描根对象和标记的效率,G1 使用了二个新的辅助存储结构:
Remembered Sets:简称 RSets,用于根据每个 region 里的对象,是从哪指向过来的(即:谁引用了我),每个 Region 都有独立的 RSets。(Other Region -> Self Region)。
Collection Sets :简称 CSets,记录了等待回收的 Region 集合,GC 时这些 Region 中的对象会被回收(copied or moved)。
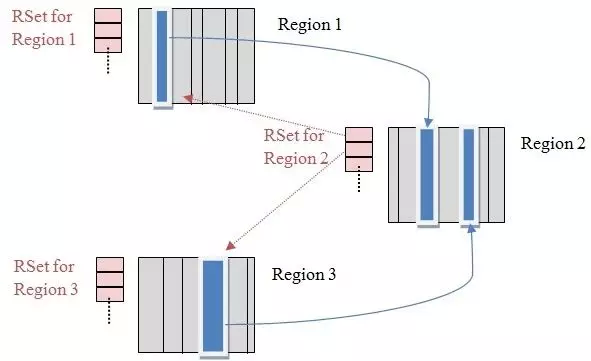
RSets 的引入,在 YGC 时,将年青代 Region 的 RSets 做为根对象,可以避免扫描老年代的 region,能大大减轻 GC 的负担。注:在老年代收集 Mixed GC 时,RSets 记录了 Old->Old 的引用,也可以避免扫描所有 Old 区。
Old Generation Collection(也称为 Mixed GC)
按 oracle 官网文档描述分为 5 个阶段:Initial Mark(STW) -> Root Region Scan -> Cocurrent Marking -> Remark(STW) -> Copying/Cleanup(STW && Concurrent)
注:也有很多文章会把 Root Region Scan 省略掉,合并到 Initial Mark 里,变成 4 个阶段。
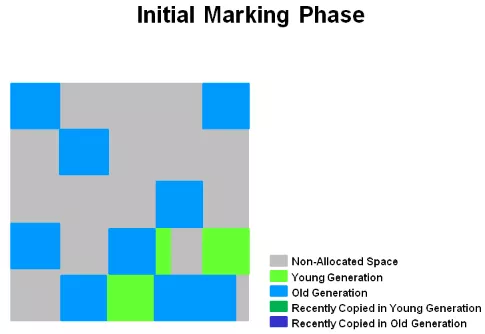
存活对象的”初始标记”依赖于 Young GC,GC 日志中会记录成 young 字样。
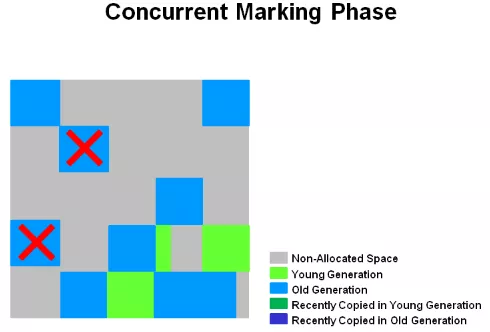
并发标记过程中,如果发现某些 region 全是空的,会被直接清除。
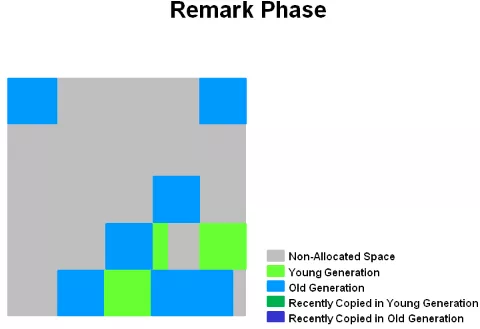
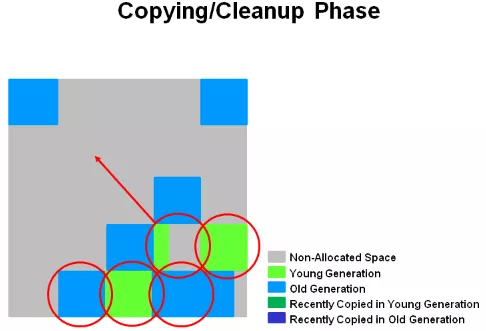
并发复制 / 清查阶段。这个阶段,Young 区和 Old 区的对象有可能会被同时清理。GC 日志中,会记录为 mixed 字段,这也是 G1 的老年代收集,也称为 Mixed GC 的原因。

上图是,老年代收集完后的示意图。
通过这几个阶段的分析,虽然看上去很多阶段仍然会发生 STW,但是 G1 提供了一个预测模型,通过统计方法,根据历史数据来预测本次收集,需要选择多少个 Region 来回收,尽量满足用户的预期停顿值(-XX:MaxGCPauseMillis 参数可指定预期停顿值)。
注:如果 Mixed GC 仍然效果不理想,跟不上新对象分配内存的需求,会使用 Serial Old GC(Full GC)强制收集整个 Heap。
小结:与 CMS 相比,G1 有内存整理过程(标记 - 压缩),避免了内存碎片;STW 时间可控(能预测 GC 停顿时间)。
8. ZGC[^5]
Java11引进了ZGC,可通过-XX:+UnlockExperimentalVMOptions -XX:+UseZGC参数打开。ZGC分为3个阶段:
- 第一阶段stop-the-world,标记GC roots。由于GC roots一般数量较少,这个阶段耗时较少。
- 第二阶段并发从GC roots出发标记可达对象。
- 最后一个阶段stop-the-world,处理边界情况,例如weak reference。
指针染色 reference coloring

指针指向OS虚拟内存中的位置,由于32位指针只能寻址4G的堆内存,而现在的应用一般都需要更多的堆内存,因此ZGC必须使用64位指针。
ZGC指针使用42 bit进行寻址,因此可以寻址4TB的堆内存。除此之外,还有4bit用于存储指针的状态。
- finalizable bit – 说明该对象只能通过finalizer可达
- remap bit – 指针指向当前对象存储的位置并处于最新状态
- marked0 and marked1 bits – 用于标记可达的对象
这些bits也称为metadata bits。ZGC中这些metadata bits中有且仅有一个为1。
Relocation 内存块迁移
ZGC中,relocation分为以下阶段:
- 并发阶段:寻找需要迁移的内存块,保存到relocation set。
- stop-the-world阶段:迁移在relocation set中的所有GC roots并更新他们的引用,即指针指向的地址。
- 并发阶段:迁移relocation set中剩余的对象,并保存旧的和新的地址之间的映射关系到forwarding table中。注意,此时并没有完成新的地址更新到指针中。
- 剩余的引用的新的地址的重写发生在下一个标记阶段。这样,我们就不用遍历两遍对象树。load barriers也可以实现这个步骤。
Remapping and Load Barriers
在迁移阶段,并没有将新的迁移后的地址更新到指针/引用中。因此,通过那些引用是无法访问到正确的对象的,甚至可能访问到垃圾。ZGC 通过使用load barriers来解决这个问题. Load barriers通过remapping技术实现将指针/引用指向迁移后的新的地址 。
当应用加载一个引用时,触发load barrier通过以下步骤返回正确的地址:
- 检查remap bit是否设为1,如果是说明已经指向最新地址,可直接返回。
- 然后检查引用的对象是否在relocation set中,如果不在说明不需要迁移它,为防止下次再检查,将该引用/指针的remap bit设为1,并返回该引用。
- 到这一步就知道引用的对象需要迁移,如果迁移是否已完成,则跳到下一步,如果没完成则在forwarding table中创建一个entry,保存迁移后的新地址。
- 到这一步目标对象已经迁移完成。我们更新引用使其指向新的地址,设置remap bit为1,并返回该引用。
由于每次加载一个引用都会触发load barrier,因此会有一点性能上的损失,尤其是第一次访问一个迁移的对象时,这是为了获得更短的暂停时间而付出的代价。不过由于这些步骤都很快,因此对应用的性能不会有太大影响。
d. GC日志, 参数与优化
GC优化相关经验不多,可以参考下面这篇文章。
https://tech.meituan.com/2017/12/29/jvm-optimize.html
e. Object.finalize() 方法与 Finalizer 类
这部分内容属于GC相关的内容,可以参考 https://www.jianshu.com/p/9d2788fffd5f [^9],此文写的比较深入,涉及到了hotspot的源码,强烈推荐。
finalize() 方法[^8]
1 | public class FinalizerDemo { |
运行这段代码,加上-XX:+PrintGCDetails参数查看GC详情,可以发现很快就开始full gc,而去掉对finalize()方法的重写则不会触发full gc。这是为什么呢?这就涉及到重写了finalize()方法的类的回收了,下面详细说一下,或者也可以直接阅读上面推荐的文章。
列一下finalize()方法相关的特性:
- 当GC判断没有其他对该对象的引用时,会调用该方法,一般用于执行资源释放或其他清理工作
- finalize()方法抛出的异常会被忽略
- finalize()方法中可以使该对象重新关联到引用链上,也即是”复活”该对象,例如,让一个静态全局变量指向该对象,使其免于被回收
- finalize()方法最多执行一次
Finalizer 类
阅读上面推荐的文章就知道finalize()方法与Finalizer类脱不开关系。下面分析一下这个类的源码。
Finalizer类有3个静态变量,2个成员变量,分别是:
| 变量 | 作用 |
|---|---|
| ReferenceQueue<Object> queue | 全局静态变量,是一个引用队列,保存Finalizer对象 |
| Finalizer unfinalized | 全局静态变量,Finalizer对象以双向链表的形式保存,该变量指向当前链表的头部,每次新创建一个Finalizer对象会将其放在链表头部 |
| Object lock | 全局静态变量,用于在对双向链表操作时加锁 |
| next | 链表中当前对象的下一个 |
| prev | 链表中当前对象的前一个 |
注意到Finalizer类的源码中有一个register方法,注释是该方法由VM调用,推测是当重写了finalize()的对象初始化时会调用register方法(推荐文章中有对这部分的hotspot源码分析),该方法会将该对象作为构造器参数创建一个Finalizer对象,Finalizer继承了FinalReference<Object>,因此构造器会将finalizee(即实现了finalize()方法的对象)和全局的ReferenceQueue作为构造参数构造Reference<Object>。
1 | private Finalizer(Object finalizee) { |
Finalizer类的runFinalizer方法就是最终用来调用对象的finalize()方法的。先判断是否已执行过finalize()方法,若没有,则从双向链表中移除自身,然后调用finalizee的finalize()方法,最后finalizee = null;这一步注释说的是清理包含这个变量的栈帧,减少false retention概率,关于false retention后面单开文章说。
1 | private void runFinalizer(JavaLangAccess jla) { |
FinalizerThread
Finalizer类通过静态初始化代码块启动一个FinalizerThread守护线程,该线程优先级较低。注意线程优先级较低这一点,正是这一点导致在上面的示例中来不及执行对象的finalize()方法,导致垃圾回收很慢,内存泄漏,触发full gc,甚至OOM。
1 | static { |
下面看下FinalizerThread的逻辑:
1 | private static class FinalizerThread extends Thread { |
主要关注最后的死循环部分,调用queue的remove()方法,取出队列中的Finalizer对象,执行其runFinalizer方法。
到这里就剩下一个疑问点,Finalizer对象是什么时候加入queue队列的?这就要说到Reference<T>类了。
Reference 与 ReferenceHandler
前面说到Finalizer继承了FinalReference<Object>,而FinalReference类继承了Reference。看一下这个类的静态初始化代码块,里面启动了一个ReferenceHandler守护线程,该线程优先级较高。
1 | static { |
ReferenceHandle线程死循环执行一个方法tryHandlePending,源码如下:
1 | static boolean tryHandlePending(boolean waitForNotify) { |
主要逻辑就是将pending链表的头节点取出,并将其加入队列中(最后3行代码),其中pending链表是GC扫描出的pending状态的Reference对象链表,Finalizer实现了Reference,也会被扫描出来,至于具体逻辑就要查看jdk源码了,这个正好在参考文献 [^9] 也就是最开头推荐的文章中有提到。
小结
回到最开始的例子,再分析一下。main函数死循环创建一个重写了finalize()方法的对象,JVM会为每一个对象创建一个Finalizer对象,ReferenceHandle线程负责将Finalizer对象加入ReferenceQueue,该线程优先级较高,而FinalizerThread线程负责消费ReferenceQueue,执行对象的finalize()方法,优先级较低。只有当对象的finalize()方法执行完,对象才能被回收。
那么当FinalizerThread线程由于优先级低而抢不到CPU资源,或者finalize()方法执行较慢等原因来不及消费ReferenceQueue时,就会出现GC无法回收垃圾,从而导致full gc。
finalize()方法最多执行一次的原理也在此说一下我个人的理解,不一定正确。上面说到,当对象创建时,如果该对象重写了finalize()方法,JVM会调用Finalizer对象的register方法,即该对象对应的Finalizer对象只会被创建一次,而一旦这个Finalizer对象被移出ReferenceQueue就不会再回到ReferenceQueue。