JVM 基础
本文大部分内容通过收集网上文章总结而来,有些标注了出处,有些由于忘记等原因没有标注出处,若发现文中内容存在原出处并且没有标注,请联系本人。
JVM 基础
先大致了解一下JVM的运行时内存结构,运行时内存结构包含了大部分需要了解甚至深入了解的JVM基础内容。
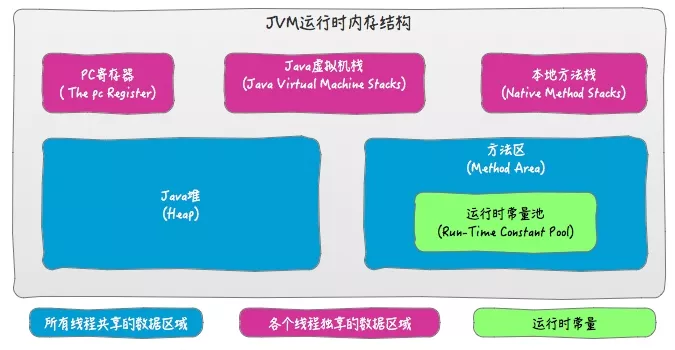
JVM运行时的内存结构分为6个区域,分别是
- PC寄存器,即程序计数器
- 虚拟机栈
- 本地方法栈
- Heap,即堆
- 方法区,方法区的实现取决于虚拟机可以放在堆的永久代,或者Metaspace(java 8)。
上述 6 个区域,除了 PC Register 区不会抛出 StackOverflowError 或 OutOfMemoryError ,其它 5 个区域,当请求分配的内存不足时,均会抛出 OutOfMemoryError(即:OOM),其中 thread 独立的 JVM Stack 区及 Native Method Stack 区还会抛出 StackOverflowError。
还有一类不受 JVM 虚拟机管控的内存区,这里也提一下,即:堆外内存。

可以通过 Unsafe 和 NIO 包下的 DirectByteBuffer 来操作堆外内存。如上图,虽然堆外内存不受 JVM 管控,但是堆内存中会持有对它的引用,以便进行 GC。
一、ClassLoader
说到jvm内存不得不先说一下类加载器,类都是通过类加载器加载到jvm中。
1. 双亲委派模型
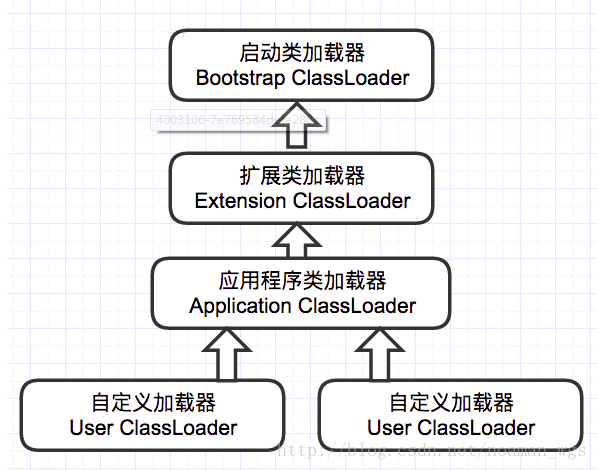
JVM默认采用双亲委派模型实现类加载机制。双亲委派模型中,类加载器是分层级的结构,一个类加载器有其parent类加载器,JVM自带的Bootstrap ClassLoader没有parent,可作为其他类加载器的parent。
采用双亲委派模型的主要原因是:
https://blog.csdn.net/21aspnet/article/details/88412989
https://www.ibm.com/developerworks/cn/java/j-lo-classloader/
### 3. Tomcat的类加载机制
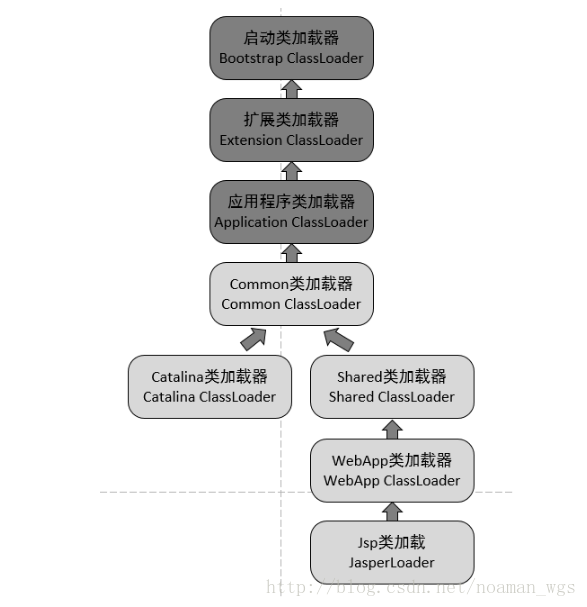
Tomcat目录下有4组目录:
/common目录:类库可以被Tomcat和Web应用程序共同使用;由 Common ClassLoader类加载器加载目录下的类库;
/server目录:类库只能被Tomcat可见;由 Catalina ClassLoader类加载器加载目录下的类库;
/shared目录:类库对所有Web应用程序可见,但对Tomcat不可见;由 Shared ClassLoader类加载器加载目录下的类库;
/WebApp/WEB-INF目录:仅仅对当前web应用程序可见。由 WebApp ClassLoader类加载器加载目录下的类库;
每一个JSP文件对应一个JSP类加载器。
## 二、堆
### 1. 从Java Object说起[^6]
Java中Object的组成:
> Object = Header + Primitive Fields + Reference Fields + Alignment & Padding
> 📖 独立文章:[Java 对象头与锁升级](/java-object-header/)
#### b. 偏向锁 biased locking[^3]
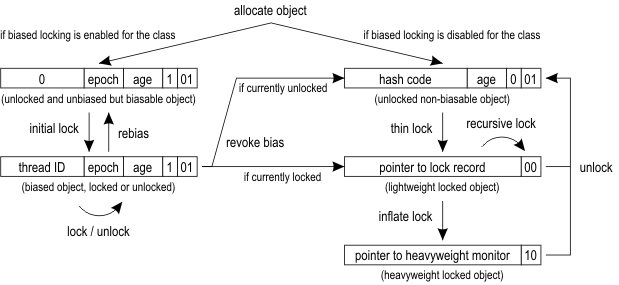
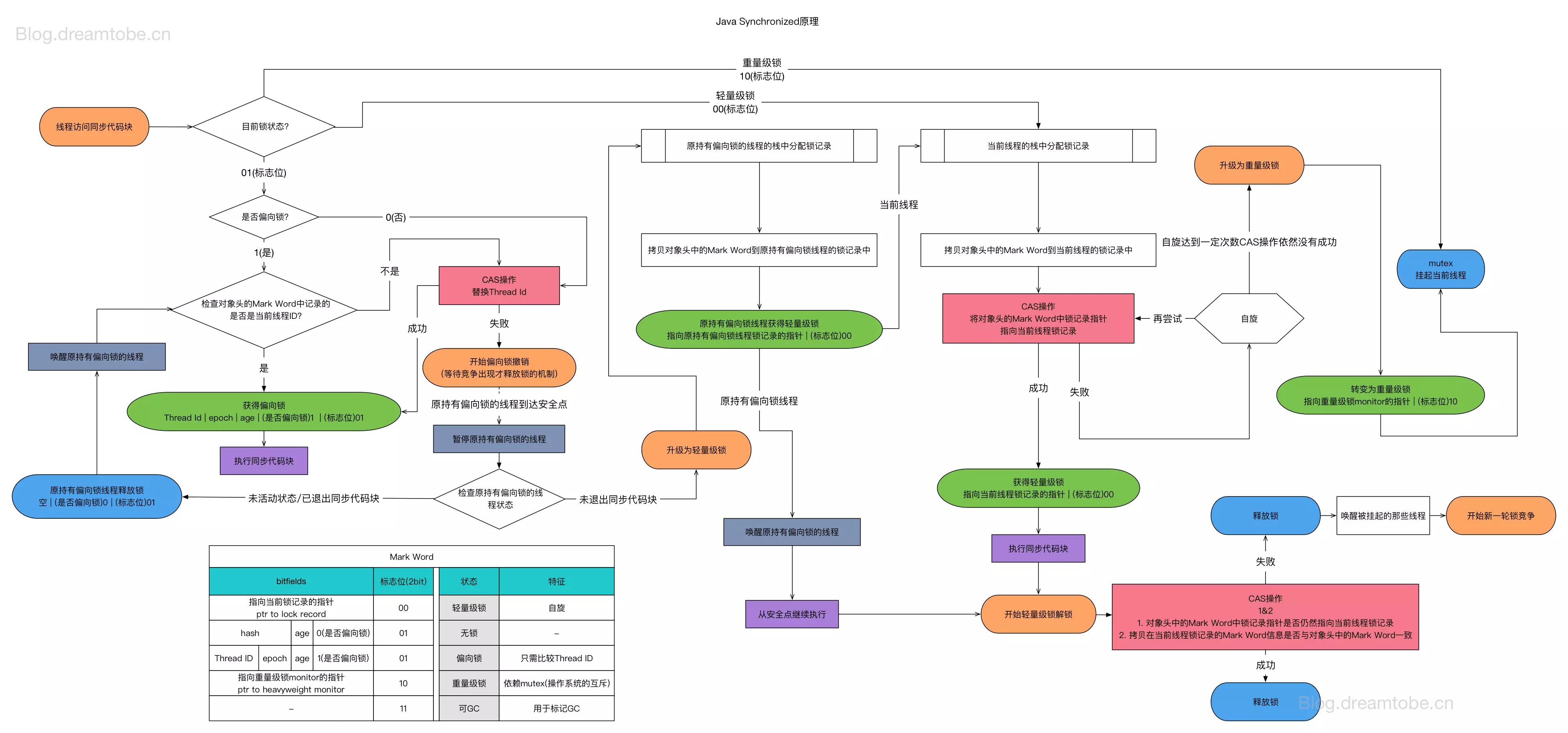
jvm利用对象头中存储的信息实现了偏向锁.
1. 偏向锁:偏向锁假定将来只有第一个申请锁的线程会使用锁(不会有任何线程再来申请锁),对象头中存线程id,通过CAS操作加锁,无法通过自旋锁优化
2. 轻量级锁:对象头中Mark Word中的部分字节指向线程栈中的Lock Record,通过CAS操作加锁/解锁,可通过自旋锁优化
3. 重量级锁:对应操作系统的mutex,成本非常高,包括系统调用引起的内核态与用户态切换、线程阻塞造成的线程切换等,可通过自旋锁优化,避免线程切换
4. 锁升级/锁膨胀:当没有竞争时(只有一个线程使用锁),采用偏向锁,当有第二个线程尝试获取锁时,升级为轻量级锁,当竞争较多时,升级为重量级锁
#### c. 对齐(Alignment)和补齐(Padding)
- 对齐:任何对象都是以8 bytes的粒度来对齐的
怎么理解这句话呢?请看一个例子,`new Object()`产生的对象的大小是多少呢?12 bytes的header,但对齐必须是8的倍数,还有4 bytes的alignment,所以对象的大小是16 bytes
- 补齐:补齐的粒度是4 bytes
可以简单理解为,JVM分配内存空间一次最少分配8 bytes,对象中字段对齐的最小粒度为4 bytes
finalize()方法最多执行一次的原理也在此说一下我个人的理解,不一定正确。上面说到,当对象创建时,如果该对象重写了finalize()方法,JVM会调用Finalizer对象的register方法,即该对象对应的Finalizer对象只会被创建一次,而一旦这个Finalizer对象被移出ReferenceQueue就不会再回到ReferenceQueue。
## 三、方法区
方法区,主要存放类信息、静态变量、运行时常量池、字段数据、方法数据、方法代码等。
- Classloader reference
- 运行时常量池 — 数字常量, field references, method references, attributes; As well as the constants of each class and interface, it contains all references for methods and fields. When a method or field is referred to, the JVM searches the actual address of the method or field on the memory by using the runtime constant pool.
- Field data — Per field: name, type, modifiers, attributes
- Method data — Per method: name, return type, parameter types (in order), modifiers, attributes
- Method code — Per method: bytecodes, operand stack size, local variable size, local variable table, exception table; Per exception handler in exception table: start point, end point, PC offset for handler code, constant pool index for exception class being caught
《Java虚拟机规范》规定了方法区的概念和作用,并没有规定如何具体实现。JDK7及之前,HotSpot虚拟机使用永久代来实现方法区,JDK8中去掉了永久代,用Metaspace实现方法区。
### 1. 运行时常量池 runtime constant pool
#### 静态常量池(class文件常量池)
编译生成的 class 字节码文件结构中有一项是常量池(Constant Pool Table),用于存放编译期生成的各种字面量(Literal)和符号引用(Symbolic References),这部分内容将在类加载后进入方法区的运行时常量池中存放。运行时常量池可以在运行期间将符号引用解析为直接引用。
- 字面量:字符串字面量和声明为 final 的(基本数据类型)常量值。字符串字面量除了类中所有双引号括起来的字符串(包括方法体内的),还包括所有用到的类名、方法的名字和这些类与方法的字符串描述、字段(成员变量)的名称和描述符;声明为final的常量值指的是成员变量,不包含本地变量,本地变量是属于方法的。这些都在常量池的 UTF-8 表中(逻辑上的划分);
- 符号引用:指向 UTF-8 表中字面量的引用
1. 类和接口的全限定名:例如对于String这个类,它的全限定名就是java/lang/String。
2. 字段的名称和描述符:这里的字段就是类或者接口中声明的变量。
3. 方法的名称和描述符:这里的描述符是方法的参数类型+返回值类型。
PS : int -128~127 范围的值也在运行时常量池中。
jdk1.8 已移除永久代,字符串常量池存储的也只是引用。
#### String.intern()
https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html
### 2. Permgen vs Metaspace
区别:
1. 存储位置不同,永久代是堆的一部分,和新生代,老年代地址是连续的,而元空间属于本地内存;
2. 存储内容不同,元空间存储类的元信息,静态变量和常量池等并入堆中。相当于永久代的数据被分到了堆和元空间中。
https://www.cnblogs.com/paddix/p/5309550.html
## 四、栈
### 1. JVM栈帧 (Stack Frame)
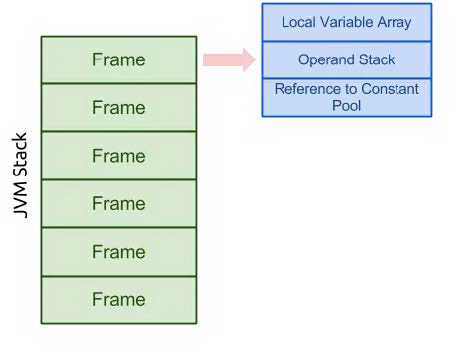
#### a. 线程
一个线程对应一个jvm stack,一个stack中包含一组stack frame。线程调用方法对应stack frame入栈,方法结束(正常返回或异常结束)对应出栈。
#### b. 栈帧
栈帧用于存储局部变量表、操作数栈、动态链接、方法返回等信息。 每个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
在活动线程中,只有位于栈顶的栈帧才是有效的,称为当前栈帧,与这个栈帧相关联的方法称为当前方法。执行引擎运行的所有字节码指令都只针对当前栈帧进行操作。
- 局部变量表:局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)「String是引用类型」,对象引用(reference类型)和returnAddress类型(它指向了一条字节码指令的地址)。
- 操作数栈:
- 动态连接
- 每个栈帧都包含一个指向**运行时常量池**中,该帧所属方法的引用,以支持动态连接
- 方法返回地址
#### c. StackOverflowError
当方法的递归调用太深时,会发生StackOverflowError错误。其他会产生StackOverflowError的极端情况还有:方法内部一直嵌套调用、方法的局部变量过多、类的构造函数间相互循环调用、类在实例化时将类的实例作为成员变量。
## 五、本地方法栈
本地 (原生) 方法栈,顾名思义就是调用操作系统原生本地方法时,所需要的内存区域。HotSpot虚拟机直接将本地方法栈和虚拟机栈合二为一。同虚拟机栈相同,Java虚拟机规范对这个区域也规定了两种异常情况:`StackOverflowError` 和 `OutOfMemoryError`。
## 六、程序计数器
PC (program counter) register 存储了当前正在被执行的JVM指令的地址。
## 七、执行引擎
有关jvm执行引擎的内容也看了不少文章,感觉不是简单能说清楚的,推荐可以先阅读以下文章:
http://wuzguo.com/blog/2017/06/23/jvm_execution_engine.html
https://blog.csdn.net/qq_33938256/article/details/52584658
https://blog.csdn.net/dd864140130/article/details/49515403
后续有机会,针对这个话题单独展开一下,下面就简单说一下之前提到的JIT编译器带来的逃逸分析。
### 1. Just-In-Time(JIT) compiler
#### JIT编译优化技术带来的内存分配变化
JIT编译除了具有缓存的功能外,还会对代码做各种优化,比如:逃逸分析、 锁消除、 锁膨胀、 方法内联、 空值检查消除、 类型检测消除、 公共子表达式消除等
JIT compiler compensate for the disadvantages of the interpreter for repeating operations by keeping a native code instead of bytecode.
## 八、内存分配优化
其实这部分属于比较不是那么基础的内容,之所以放在这里是因为在写这篇文章的过程中,发现坑越挖越多,越挖越深,只好把已经挖的坑先填一填,难受。
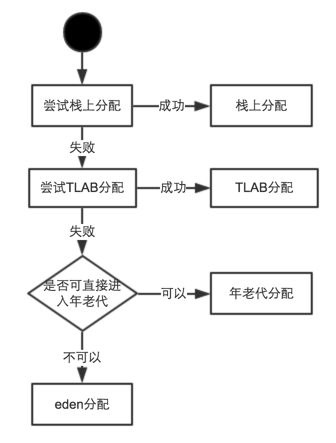
### 1. 栈上分配与标量替换[^7]
这部分其实是jvm对内存分配做的优化工作,通过逃逸分析判断局部变量是否会逃逸出线程调用栈,若不回则进行栈上分配,如果是基本类型的变量则进行标量替换。
相关启动参数:见上面逃逸分析部分。
### 2. bump-the-pointer和TLAB allocation(Thread-Local Allocation Buffers)
应用程序的对象大部分是由线程创建并分配内存的。
HotSpot虚拟机使用了两种技术来加快内存分配。他们分别是是**bump-the-pointer**和TLABs(Thread-Local Allocation Buffers)
bump-the-pointer
TLAB allocation仍然是堆的一部分,从它的名字中的Thread-Local就可以看出,只不过这部分buffer是单独分配给线程进行内存分配的。
https://www.jianshu.com/p/8be816cbb5ed
https://blog.csdn.net/yangzl2008/article/details/43202969
https://dzone.com/articles/thread-local-allocation-buffers
https://blog.csdn.net/yangsnow_rain_wind/article/details/80434323
https://shipilev.net/jvm/anatomy-quarks/4-tlab-allocation/
https://blog.csdn.net/zhou2s_101216/article/details/79221310
https://www.jianshu.com/p/580f17760f6e
https://juejin.im/post/5c151b266fb9a049ac790d9a
https://segmentfault.com/a/1190000016960388
## 九、JVM系统线程
除了开发者在java应用中创建的线程,jvm中还有许多系统创建的系统线程,这些线程完成许多jvm内部的任务。
### 1. main thread
对应`public static void main(String[])`方法的系统线程。jvm先启动一个main线程,然后去调用指定的类的main方法。
### 2. Compiler threads
Compiler线程在运行时将字节码编译成机器码。
### 3. GC threads
GC线程负责GC相关的操作。
### 4. Periodic task thread
The timer events (i.e. interrupts) to schedule execution of periodic operations are performed by this thread.
### 5. Signal dispatcher thread
这个线程接收发送给JVM的信号,并调用相应的JVM方法进行处理。
### 6. VM thread
As a pre-condition, some operations need the JVM to arrive at a safe point where modifications to the Heap area does no longer happen. Examples for such scenarios are "stop-the-world" garbage collections, thread stack dumps, thread suspension and biased locking revocation. These operations can be performed on a special thread called VM thread.
# 小结
本文是个人在查找阅读许多文章的基础上总结得来,其中部分内容经过个人实际试验,但大部分内容乃是前人的经验总结,在此深表感谢。在写本文的过程中,发现JVM体系庞大,越挖越深,颇有"吾生也有涯,而知也无涯"的感触,也总结出一个字,学!!!
# 参考文献
[^1]: https://juejin.im/post/5c4c8ad9f265da6179752b03
[^2]: https://gist.github.com/arturmkrtchyan/43d6135e8a15798cc46c#file-objectheader64-txt
[^3]: https://wiki.openjdk.java.net/display/HotSpot/Synchronization
[^4]:https://www.baeldung.com/jvm-compressed-oops
[^5]: https://www.baeldung.com/jvm-zgc-garbage-collector
[^6]: https://segmentfault.com/a/1190000012354736
[^7]:https://juejin.im/post/5c151b266fb9a049ac790d9a
[^8]: https://www.cnblogs.com/benwu/articles/5812903.html
[^9]: https://www.jianshu.com/p/9d2788fffd5f